Data Type
- Computer 내부
Code
- language > Statement > Word > Character
종류
숫자
- Integer
- Float
문자
- Character
- Ascii (조사)
- Unicode (조사)
| CPU | Memory | IO Device |
예) 메모리 할당
- int x
x -> @100
y -> @104
- x = 3
@100 = 3
숫자 타입
Integer - 4 byte
예) int x, x = 3
000000000000000000000000000000000011
Inter Device Coummunication
- 계산을 해야하기 때문에 계산용이다.
계산 용
- 3+1
Alphabet 표현 방법
- 표준 코드
- Character Type
- Char A:
- 초기에는 8bit = 1 Byte - ASCII
0 0 0 0 0 0 0 0 0
- 외국어 16bit = 2 Byte - Unicode
- 계산
- 0x32 - 0x33 = 0x65 (e)
순서를 더한 것이다. 아스키나 유니코드나 숫자는 같다.
내부의 계산형 data type과 사람과 소통할 때 필요한 문자 type하고는 전혀 다르다.
0 0 1 1 / 0 0 1 0
0 0 1 1 / 0 0 1 1
0 1 1 0 / 0 1 1 1
예) 메모리 할당
- int x
x -> @100
y -> @104
Data Type - 랭귀지의 단어에 해당되는 것이 Data Type
CPU는 숫자를 2진법으로 계산한다. 여기서 숫자가 있으면 8이되는 숫자가 있으면 0 1 0 0 0 이 8이다. (2진법)
89를 쓰고 싶으면 0 1 0 0 0 / 0 1 0 0 1 (2진법이여서 어디서부터 어디가 8이고 9인지 모른다)
명령어인지, 숫자인지, 아무것도 모른다. 컴퓨터는 끝도없이 0과 1만 가질 수 없다.
어떤건 숫자고 문자인지 어떻게 정리를 할까?
- 띄어쓰기하잖아. 여긴 띄어쓰기가 안된다. 방법이 없다.
띄어쓰기도 원래 글자다. space는 아무것도 없는 것이아니라 space라는 캐릭터가 있는 것이다.
size를 고정시켜서 쓰는 것이다.
int는 4byte씩 쓴다. Int x y 라 쓰면
계산용 숫자는 2진법으로 표현되지만, 사람이 쓰는 것은 글자여서 내부의 2진법과는 다르다.
파워포인트에 3을 쓰던 4를 쓰던 글자로 취급된다.
내부에서 계산을 위한 int와 사람이 보는 alphabet과는 그것이 비록 숫자이겠지만 매우 다르다.
그래서 모니터같은 경우에는 코드를 만든다.
2 0
1자릿수가 4byte이다.
그래서 핵사 number을 잘 쓴다
16진법을 보면 편하다
2의 4는 16이다. 그래서 16은 4byte
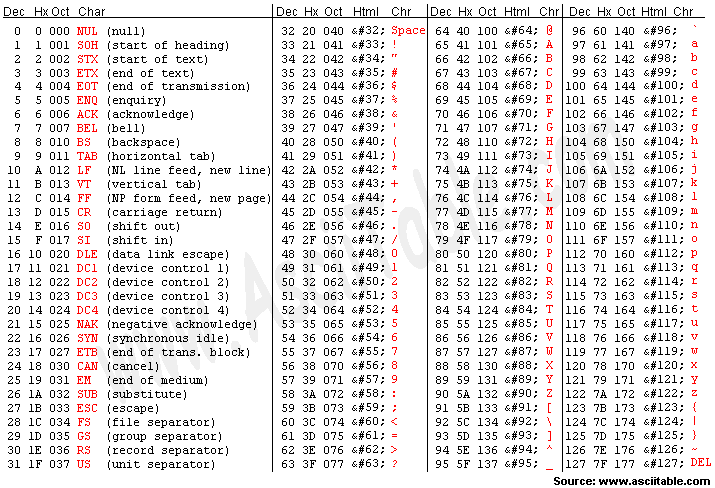
Hx 2 0 space 숫자가 30 대문자 A 41 소문자 a 61
미국에서 만들 때에는 128자면 많다 생각했는데 한자가 있으면 몇 만자여서 들어가지도 않는다.
그러니까 2byte로 늘렸는데 이 것을 유니코드라고 한다.
2의 16승은 40000자가 넘어간다. 그것도 모자라면 4byte로 가야한다. 4byte까지 갈 수 있다.
지금은 유니코드가 2byte를 쓴다
한글도 실제로는 뜯어져있지 않다. 한글은 모든 경우를 코드로 만들어놨다.
이유: 조립해서 쓰면 이쁘지가 않다. ㄱ,ㅋ 등
유니코드 unicode 표
계산할 때 숫자는 2진법으로 값이 들어간다. 컴퓨터에서 숫자와 문자는 전혀 다르다.
순서가 다르다. 어떤 문자가 몇번인지를 정리해놓은 것이 코드다.
microsoft에서 정리한 것도 다 다르다. 그것을 인코딩이라고 한다.
어떤 코드스킨, 코트테이블을 쓰는 것에 따라 글자가 바뀐다.
아스키코드: 정보 교환형 미국 표준식이다. 63년에 나왔다. 처음에는 128자만 했다가 ~
똑같은 Integer이여도 2,4,8byte
flaot 2,8,16byte가 있다.
언어에 따라 다르다.
Java에서는 어떻게?
키보드에서 a라는 자판을 때리면 61 컴퓨터 본체가 코드가 61이 나온다.
ascII코드 61이 딱 들어온다.
scan f 같은거는 유니코드가 들어온다.
6100 hx로 들어간다.
메모리를 확보해놨다가 저장하면 나중에 모니터에 저장하면 모니터에 a가 나타난다.
character로 23을 쳤어. 2+3을 쳤어. 2가 들어올 때 32가 아닌 0000000010
키보드에서 칠 때에는 character로 들어오는데 계산을 해야한다. 처음에 2로 계산했다가 2에다 10을 곱하고
한자리 들어오면 200이 들어오고 5를 쳤으면 535가 되어야한다.

과제
* 조사하는 것
- Information Interchange Code에 대한 종류
- ASCII
- Unicode
- Data Type (내부형태,소수점처리 등..메모리/Integer:+,-,sin 2의보수, float:10의 몇승인지,Character은 유니코드와 아스키코드가 다르다 유니코드 종류가 몇가지가 있는지)
- JAVA
-> Integer, Float, Char, Boolean
* 프로그래밍 숙제
- Scan f 하면 안됨, 자동으로 문자로 들어가도 숫자로 변형함
Keyboard 입력
- System.in.read로 한 Char씩
- 입력
숫자* => int로 변환
+
숫자* => int로 변환
=
모니터에 결과 출력
ex) Sample Code e
Int input;
Add () (
Char a;
A = System.in.read();
While (a >= 0x30 && a < 0x40) { //숫자만
// input .......
A = System.in.read();
}
}
/* 입력
ex) Sample Code e
Int input;
Add () (
Char a;
A = System.in.read();
While (a >= 0x30 && a < 0x40) { //숫자만
// input .......
A = System.in.read();
}
}
/* 입력124+34= 124 출력 */
- Java keyboard 입력
- character입력 함수를 찾아라
java keyboard char 입력 함수 찾기
System.in.read
scan f 쓰지마
System.in.read();써
char a = (char) System.in.read();
숫자를 쳐서 입력한다. read이용